AI Solutions
We design, train, and deploy AI models in controlled enterprise environments where highly sensitive corporate data stays protected. Local training pipelines, private inference, and strict security controls reduce leakage risk while enabling measurable process optimization.
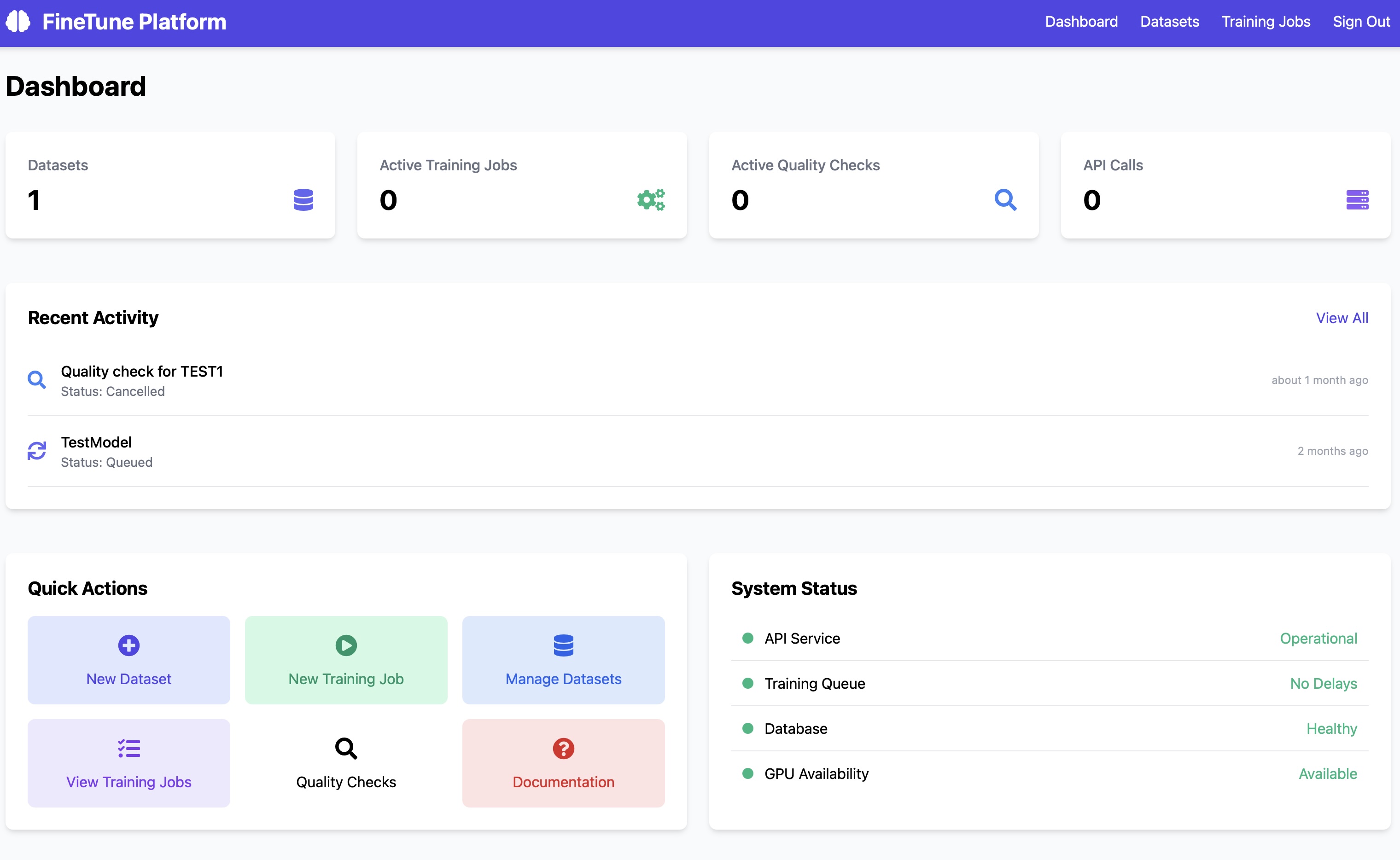
Separate AI Pricing for Inference and LoRA Training
Clear token-based pricing in a tabular format, plus dedicated compute rates for training workloads.
Interference API Pricing by Model
| Type | Price |
|---|---|
| GPT-OSS120B Input Token | $0.15 / 1M tokens |
| GPT-OSS120B Output Token | $0.50 / 1M tokens |
| Second Model Input Token | On request |
| Second Model Output Token | On request |
All costs are billed per 1 million tokens.
LoRA Training Pricing by Model
- Dedicated GPU time
- Model size (for example GPT-OSS120B base)
- Training tokens processed
- Engineering and deployment overhead
GPT-OSS120B Base Compute Rate: $2.00 per dedicated GPU hour
| Type | Price |
|---|---|
| GPT-OSS120B Input Training Token | $0.80 / 1M tokens |
| GPT-OSS120B Output Training Token | $1.80 / 1M tokens |
| Second Model Input Training Token | On request |
| Second Model Output Training Token | On request |
Token pricing is billed per 1 million training tokens.
Enterprise and Large-Scale Training Requests
For enterprise training programs and larger training volumes, please submit a request through our contact form. Final pricing can vary depending on scope, infrastructure needs, and deployment requirements.
Request Enterprise PricingBusiness outcomes and delivery value
Local AI training and private model deployment for process optimization with high-sensitivity data protection.
- Secure AI adoption without exposing highly sensitive enterprise data
- Reduced leakage risk through local training and private model operation
- Process optimization in critical workflows with domain-adapted models
Built for business and engineering teams that need AI value while keeping high-sensitivity enterprise information protected.
Trust and proof elements
- Data Protection: Local training and private inference boundaries
- Leakage Control: Segregated architecture with auditable access controls
- Deployment: Secure model rollout for high-sensitivity process optimization
Reserved for customer references, standards alignment, and approved proof assets.
Core capabilities
- Local model training in customer-controlled environments (on-premises or private cloud)
- Private model deployment for high-sensitivity information processing
- Enterprise data integration with strict segregation and governance controls
- Security architecture to prevent unintended data leakage
- Performance analytics and continuous optimization for business processes
Typical operating contexts
- Organizations processing confidential or highly sensitive enterprise data
- Teams that require AI in controlled, non-public environments
- Enterprises optimizing critical processes under strict governance requirements
Product and delivery snapshots
Main dashboard for model lifecycle visibility and operational status.
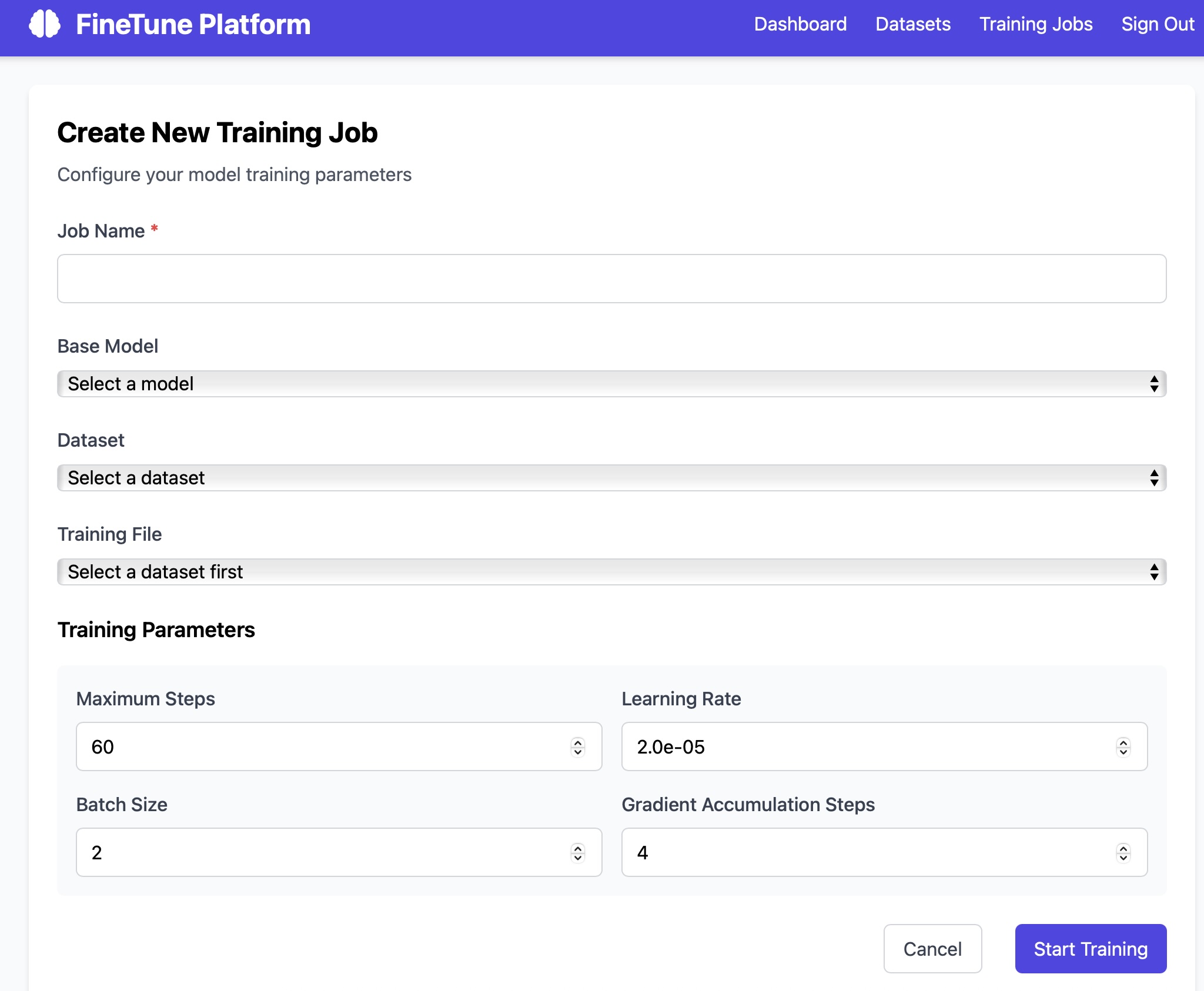
Training workspace for controlled finetuning and validation.
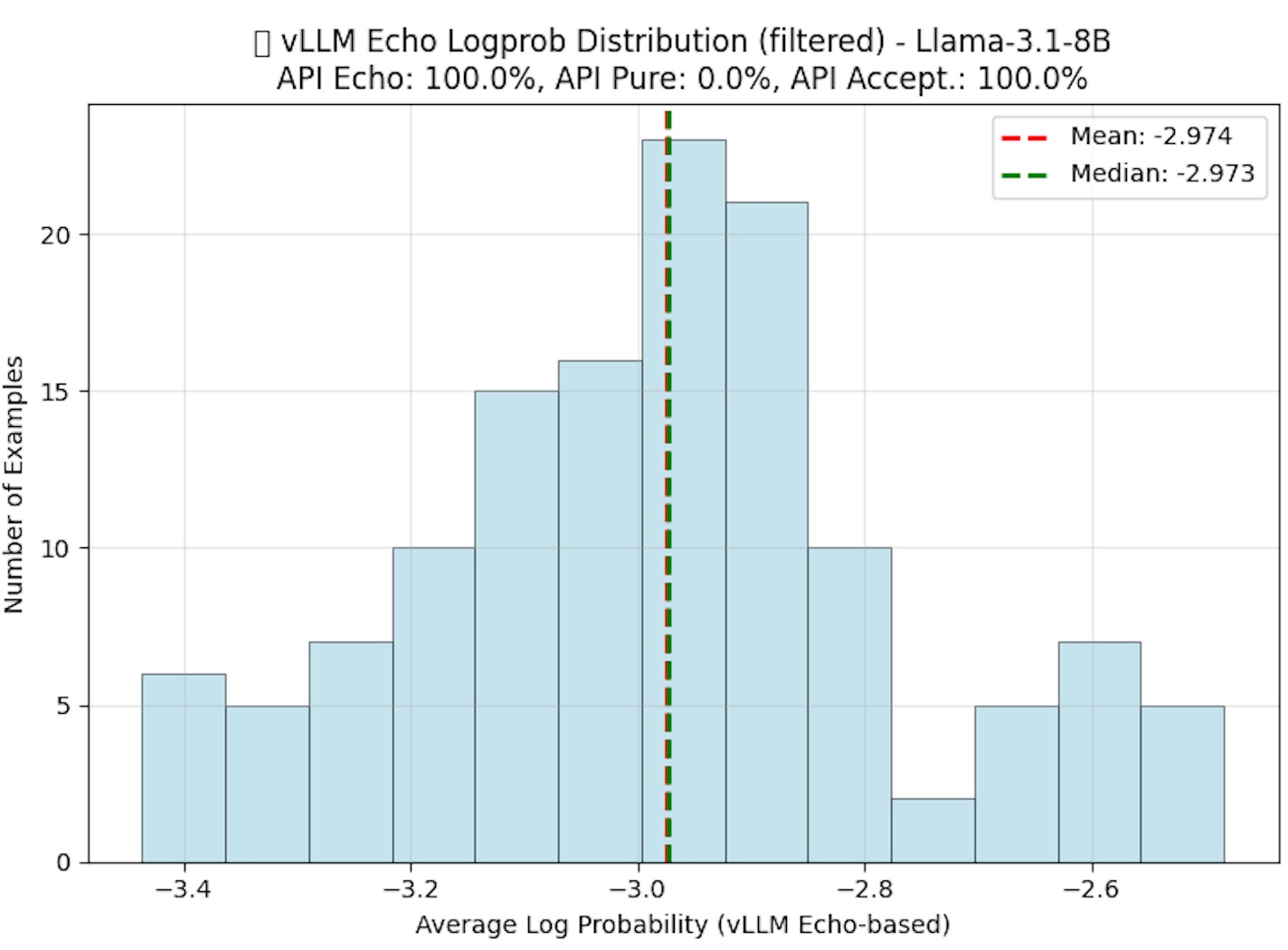
Dataset optimization using log probability analysis for better training quality.
Four-phase execution for predictable outcomes
Assessment
We evaluate risk exposure, operating maturity, and technical dependencies to establish a defensible baseline.
Roadmap
We prioritize initiatives by impact and effort, with explicit owners, milestones, and measurable targets.
Implementation
We execute technical and organizational changes through controlled rollout and documented standards.
Monitoring
We continuously track performance, risk signals, and improvement opportunities to sustain outcomes.
Adjacent capabilities in the portfolio

Cyber Security Services
Enterprise security architecture, hardening, and governance for business-critical environments.
Delivered by teams who work directly with IT operations and security stakeholders.
View Details
Mobile Device Management (MDM) as a Service
Android Enterprise and iOS enrollment services with Zero-Touch, Device Enrollment (DEP/ADE), and optional PointMobile advanced feature integration.
Our delivery model keeps Android enrollment cross-OEM and adds PointMobile-specific advantages only where they provide measurable operational benefit.
View Details
Asset Database
Independent, vendor-neutral asset management for devices, batteries, and cradles.
Built for operations teams who need to maintain asset history across disconnected systems.
View DetailsInterested in this service line?
We define scope, priority, and delivery milestones before implementation begins.